Good Luck, Good Bye
On January 4th 2026, E Street Shuffle was officially “closed for business”. The shutdown was announced a few months prior, and occurred on the eighth anniversary of the blogs founding. There would be no more updates, no new posts, no new analyses of Bruce’s catalog, no new “on this day in Bruce history” recaps, or anything else for that matter. While yes the site is still accessible, and will be until late 2027 or early 2028, the content of the site will be meeting a very different fate. Over the next two years, E Street Shuffle is being “stripped for parts” so to speak as it is compiled into book form. Which effectively means the site will be dead long before it’s death day.
But, what if it didn’t have to meet that fate?
Announcing The E Street Shuffle Archive
Link: https://lilbud.github.io/shuffle/
The E Street Shuffle Archive (as the name suggests) is an archive of E Street Shuffle. One that reproduces the layout/function of the site as well as the reproducing all of the content from ESS before it shuts down for good.
This site is the end result of several months of archival efforts, an on-and-off process with a few false starts and complications along the way. For these reasons, it took longer than I initially thought it would, and ended up in a final form I hadn’t even conceived of until about a month ago. All of this and more will be covered in this post.
Although before that, I want to get the bad news out of the way
Unannouncing The “E Street Shuffle eBook Project”
The previously announced series of eBooks compiling the site’s content will not be happening. Instead being replaced by the The E Street Shuffle Archive website. Sorry to anyone who was anticipating being able to read Ken’s writing on your Kindle while taking a dump.
There are a few reasons for this, with the main one being that once I started working on it, I realized it wasn’t as feasible as I thought it would be.
The first issue is that the eBook format really isn’t designed to archive a website. E Street Shuffle is something of a self-contained ecosystem in a way. One with posts that reference and link to other posts on the site. On a website, while reading one post you can click the link to another, read it, and return to your original post. In an eBook, the process isn’t as smooth, jumping to another section (or book) and not really having an easy way back to your starting point unless you have bookmarks or take a ton of notes or something like that.
This linking issue would lead to other problems, namely that for the links to the other posts to work, they’d all have to be in the same book. Or alternatively, I’d have to go through all 2000+ posts and rewrite every link to instead direct the reader to go to another book and chapter. Neither is ideal, nor do they sound all that fun from a user point of view.
The second issue had to do with the toolset I was using. I went with StandardeBooks, which has a robust toolset and guides on eBook creation. However, in addition to the format issues above, it was simply a convoluted PITA to use. The process to create just one book involved:
- generate body.xhtml from MD files
- split body into chapter files
- clean the files with their toolset
- run a check to ensure quotes and other type is proper
- create the title page
- create the manifest
- create the spine and metadata
- create the table of contents
- clean these final files
- run their linter to catch any other errors
- fix and rerun linter until good
- generate book
This was a finicky and somewhat annoying process that required a few attempts to even GET a finished eBook out. Even when I had that, there was still the need to proofread potentially thousands of (virtual) pages looking for errors, which would result in having to repeat the above process over and over again. This isn’t to say that the toolset is bad, just not a good fit for this kind of project. I think it’s better suited for actual books, and not something “interactive” like this.
It was also this time that I came to the realization that an eBook simply wasn’t going to be a good fit for this kind of project. Even if the process was smoother (and I’m sure if I stuck with it, I could’ve gotten it down to a science), trying to make an eBook out of a website simply wasn’t going to work without a ton more work that I really didn’t have the desire to undertake.
With that idea in the trash, I had to look for another option. The idea behind the books was a good one, being a novel (heh) and user friendly way to present and preserve the site’s content. Much the same as the idea behind the bookshelf collection (although without that concepts flaws which I covered a few months back).
While the archive exists in a few forms (Markdown/JSON, as well as a PostgreSQL database), neither of those formats was what I’d consider “user-friendly”, closer to the opposite actually. JSON isn’t a human-readable format, and Markdown (while perfectly readable even without formatting) wasn’t that well organized. I wanted a version of the archive that checked all the boxes:
- Preserves the site’s content
- Nicely organized and presented
- Easy to use
- Accessible
- Easy to share/reproduce
There wasn’t any point in the archive if people couldn’t use it. Sure, in it’s current forms it preserved the site’s content long term, and anyone could clone the repo and have a local copy, but it fails in terms of presentation/accessibility
Ideally, the best option would just be to keep the original site around forever. People are familiar with it, and it presents everything nicely. Unfortunately, nothing on the internet lasts forever. The ESS site only has another year or two until it vanishes forever, although the same can’t be said for the content which started disappearing back in November.
But, what if we could keep the original site around forever, WITH all of it’s content? Surely that would work right?
Lilbud Ignores The Archive For Several Months
To provide a bit of a timeline, it was the middle of January when the eBook idea fell through. With no immediate ideas for the archive, I put the project on the back burner for a bit. I instead focused my efforts on Databruce as well as the Radio Nowhere archive project. The ESS archive was still going in the background, as I set up a GitHub Action to fetch the latest posts every day. This ended up being a good thing, as it managed to save many posts that were added and deleted during this time.
However, I wasn’t actively working on the archive. Aside from a brief bit in March when I cleaned up some posts, there wasn’t any work being done on it.
Around the end of April, I started thinking about it again. My other main projects (Databruce and Radio Nowhere) were both in a good spot, neither requiring a ton of attention. With my time free, I started thinking about the ESS archive again. I knew that I had to go back and finish it, otherwise it would go on forever. Past projects of mine either wrap up quickly (Backstreets Magazine), or drag on seemingly endlessly.
The main problem was solving the issue of not having that easy user-friendly way to browse the archive. But, like many of my better ideas, it started as a “wait that is just crazy enough to work” idea and snowballed from there…
“What if I just recreated the ESS site?”
Inspiration Move Me Brightly
While the idea seems obvious now, I genuinely didn’t even consider the idea until that “A-HA” moment in April. Till then, I wasn’t sure what I was going to do with the archive. I thought maybe I’d revisit the books at some point, or just publish the database/loose files and call it.
However, the idea was better than I thought. More than just preserving the content of the site, it would also preserve the experience of using the site. The site is good for many reasons, why fix something that isn’t broke?
With that, now I just had to figure out how the hell to do just that.
Dr. Jekyll
Jekyll is a static site generator, designed primarily for blogs and documentation sites. I use it for my personal blog site which you are reading this on right now. It’s simple, easy to use/work with, and Jekyll sites can be hosted for free on GitHub Pages. More to the point, Jekyll solely uses Markdown as the main file format for writing posts. Seeing as I had a ton of markdown files, and needed a way to present them, this sold me.
Seeing as I am also familiar with Jekyll (having had a number of sites built upon it), it was going to be the best option to proceed (for now…).
From WordPress to Jekyll
E Street Shuffle is a fairly standard WordPress site (I assume). Aside from a custom theme and some plugins, there wasn’t anything that would present any issues when it came to reproducing it.
For my version, I used Bootstrap for the frontend. Like Jekyll, I’m familiar with how it works, and I knew it would be simple enough to adapt for this project. Most everything can be customized with CSS, as I knew there would be a good bit of that needed to recreate the look of ESS.
With just Bootstrap and peeking around in Dev Tools, I had a fairly convincing copy of the site within a few hours. Hardest parts being the post title card, which does some odd things with responsive sizing. As well as the comment section, which was tricky to figure out with the sizing and padding of nested comments. Everything else was fairly seamless.
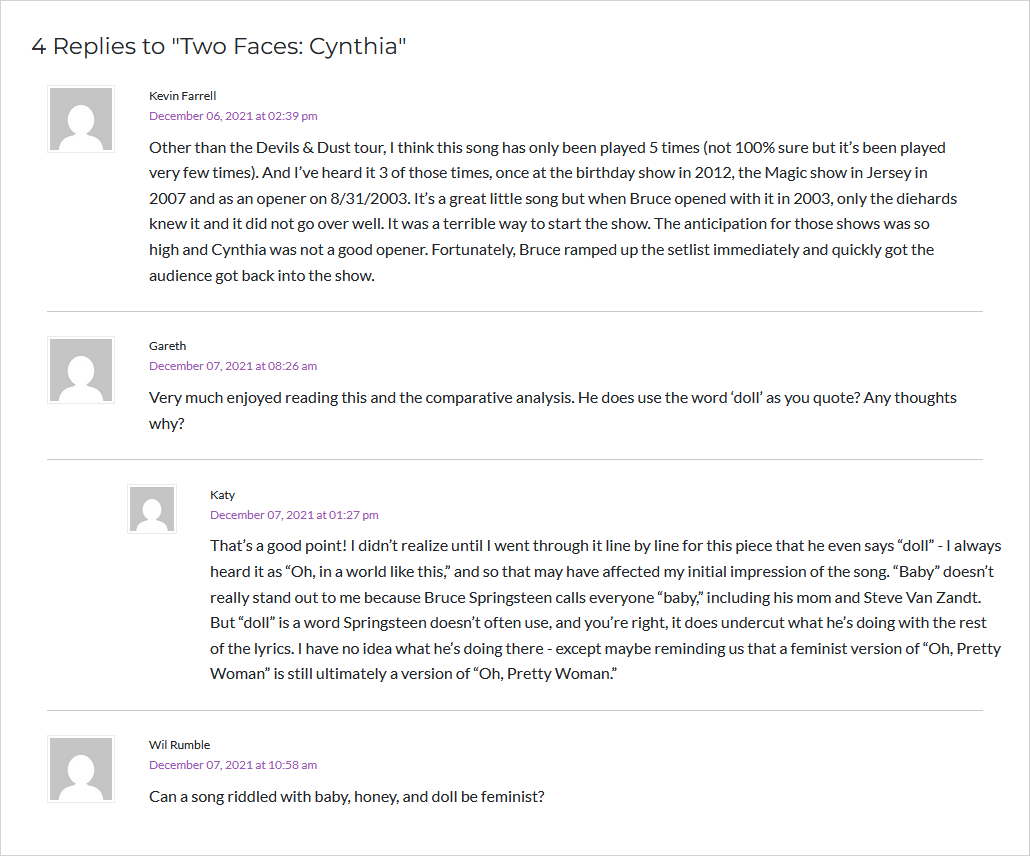
There were a few things I either couldn’t recreate or opted to leave out. The sidebar on most pages I felt wasn’t needed, as it has two slideshow elements of recent posts (recent as in Sept 2024). The calendar also felt a bit unnecessary and clunky. Those were replaced with a category select dropdown, as well as an author dropdown. On post pages, the sidebar has been removed and the post is centered and fills more space now.
There were a few things I added, mostly due to personal taste, as well as fixing things I thought could’ve been done better. The aforementioned category/author dropdowns replacing the sidebar on most pages is one. Another being new dropdown menus on the “Cover Songs” and “Original Songs” pages. The former allows quicker navigation to specific songs. The latter allows quicker navigation to specific albums. Both improve the site experience I think, with both pages being quite long with no navigation originally. The last major change being that quotes are now formatted better, before they were just blocks of italic text, but now are centered and have a different background color and colored bar to to better indicate that it is a quote.
I didn’t want to change a ton, as I wanted this to be as close to the original site as possible, both in looks as well as functionality. Preserving both the experience of using the site, as well as the content (which the other forms of the archive only do the latter).
As a last note on the design, it got so close that at times I’d click on something on my site thinking I was actually on ESS, only to be met with a 404 page because I hadn’t actually built that page yet.
Populating The Site
With the basic design done, I now had to go through and add all of the posts. Which was difficult for a few reasons.
I first had to sort through all of the archived posts and pick the most up to date version of each one. At it’s peak, there were nearly 2,100 unique posts on the site. My archive comes in at over double that. This includes post revisions, replaced posts (where the content was replaced for the bookshelf collection without updating the ID), as well as new and updated posts from the bookshelf collection. The headache of sorting through all this is part of what led to the several month break I took from it.
For most posts, there was only one version, easy enough. In the case of those with revisions, the latest versions were used. For those that have gotten updates with the Bookshelf Collection, then those were used instead.
In the end, I had 2,083 posts, with the following split:
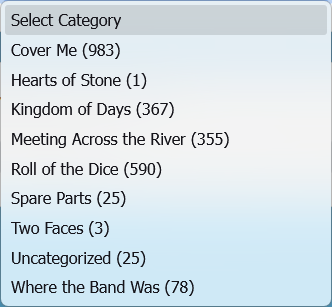
With only 2 exceptions that I know of, this is every single post that was present on E Street Shuffle prior to the shutdown and (unfortunate) mass deletion of content that started in November 2025 and is still ongoing.
Before being added to the new site, a ton of cleanup work was needed before that could happen.
A Section on Formatting Which I Swear Is Interesting
The posts were taken from the JSON dumps gotten from the API. These were stored as HTML, and had to be converted to markdown using the html_to_markdown library. While this got me most of the way, there was a metric ton of issues in the original HTML that led to formatting issues after being converted to markdown. These all had to be fixed, which was accomplished by using both VS Code’s “Find and Replace” feature, as well as numerous regex fixes in Python. The code can be seen in the “convert.py” file in the shuffle-archive repo, and I will likely document as many of them as I can in a separate file.
Once the cleanup was done, or as done as I was going to get, it was time to get them all added to the Jekyll site. For almost all of them, this just meant adding the YAML Front Matter (post metadata). For those with links to E Street Shuffle, I had to replace those links with the proper local file equivalents.
Many posts also had embedded content from Youtube or Videopress. These were first changed to a standard markdown link, with the video title added to the display text. This makes sure that even if the video is taken down, the reader can know the video that was there, and can then look it up on their own. Later on I figured out how to also add back the video embeds underneath these links. So now the nice embed is shown in addition to a fallback option.
All of this work was necessary in some form or another. But with it done, every post is now nicely formatted in plain text markdown. This is a benefit to both this site, as well as any future efforts utilizing the sites content.
Finally Getting The Site Together
With everything cleaned and imported to the site, I started the process of building the Jekyll site. This is handled by Jekyll, and handles rendering all of the posts and layouts and building the site structure. This is very useful, and I assume is similar to other site generators.
However, Jekyll has one major flaw…
The Jekyll Build Process Is Slow As Shit
When developing a site in Jekyll, it’s recommended to use the limit-posts flag when running the server, which limits how many posts are built into the final site. Very quickly I realized that this was less a recommendation and more a requirement when developing a Jekyll site.
Even with a “sensible” amount of posts (100 in my case), a build can take upwards of 3 minutes, which for a simple site with not a ton going on is pretty ridiculous. Despite taking as many steps as I could to try and get this time to something “reasonable”, it was to no avail. To the best of my knowledge, while Jekyll doesn’t have a limit to so speak, there is definitely a soft limit at play here. One where the dreadfully long build times outweigh basically any other benefits that Jekyll might provide. These long build times only became more of an issue as I got closer to the finish line.
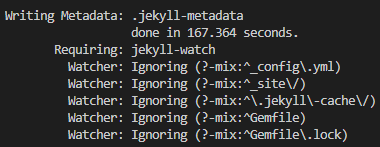
As mentioned above, while developing I would only load 100 or so posts to reduce the build time and make the process less of a pain. --incremental (only modified pages are rebuilt, rather than everything) was also used to cut down on the rebuild time (which wasn’t as bad but still noticeable). Eventually, I would have to do a full build of the site with all 2,100 posts so it could be published. While I knew the build times were long, I wasn’t quite prepared for just how slow.
I never managed to complete a full build with Jekyll. The furthest along one got was maybe halfway through rendering the posts, and that took over 30 minutes before I pulled the plug. I don’t think a simple static blog should take this long to build. Far as I can tell, this is a flaw with either Jekyll or Ruby, and not much can be done about it. Aside from limit-posts and incremental, if your site has a significant number of posts then you will be suffering through a long-ass build time.
My progress was essentially ground to a halt here. The finish line was in view, and I had a mostly finished site that I couldn’t even test in it’s “final” form due to the inability to build the site in any reasonable amount of time.
Even if I had to start from scratch, something had to be done.
Mr. Hugo
I had first heard of Hugo a while back. Like Jekyll, it is a static site generator with a focus on blogs and documentation sites. It has a similar templating/layout system, and even a similar syntax to Jekyll (which would make porting over easier). The big promise was that it was much faster than Jekyll, significantly faster even.
Since my core issue with Jekyll was the slow build times, I didn’t need much convincing. Even promising to halve the build time would’ve been enough, or hell, actually finishing a build at all.

While yes it meant having to learn an entirely new system/language and likely having to redo most of my work, the potential improvements to build speed meant it would be worth it in the long run.
Getting started with Hugo, after the initial setup and ensuring the server ran correctly, I wanted to test the build speed. Because if the improvement was minimal or nothing then I wasn’t sure what I was gonna do. Maybe have Jekyll run overnight to build the site then push to the GH repo.
My first direct comparison between Jekyll and Hugo was just to test how long it took to build and get the server up and running. Jekyll was limited to the first 100 posts, and Hugo (not having a similar option) I copied over the same 100 posts. I thought maybe it would be a minute faster, maybe two if I was lucky, but I didn’t want to get my hopes up.
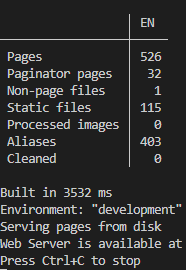
Three. Seconds.
I couldn’t believe my eyes, thinking maybe something secretly broke or the server wouldn’t actually load but no. It built the same content in 1/60th of the time as Jekyll. That sealed the deal and got me to fully move over to Hugo for the remainder of this project.
Migrating from Jekyll to Hugo was a process that (I assumed) would be a long and arduous one. In reality, it took 3 days. I already had everything done, and just had to adapt everything to the Hugo system. Aside from syntax differences, they’re very similar when it comes to templating and layout. This made the process very smooth.
Hugo also has some features I was able to take advantage of that I wasn’t able to with Jekyll. For example:
- Similar Posts: Hugo has a feature to load posts similar to the one you’re reading. Jekyll has this, but since it isn’t an “officially supported” plugin by GH Pages, you are forced to build your site locally and push it to the repo. Considering that I was unable to build even a portion of the site in Jekyll in a reasonable time, this presented an obvious issue.
- Link Verification: When building the site, any internal links with the
{{< ref POST_URL >}}tag are checked to ensure they exist and will stop the build if they don’t. It caught about a dozen or so links that didn’t exist (or did, but at a different URL), and I was able to fix those. Probably better than having to fix them piecemeal as people reported them.
I obviously didn’t get too deep into Hugo and all it can do. I only switched over to solve a problem, and used the bare essentials to do so. Hugo obviously has a ton more that it can do, and I might one day get around to that. But I really wanted to wrap this project up before it dragged on forever.
Time to Build The Damn Thing, Again
After a few days, with a functioning copy of the site. I was once again faced with adding the rest of the posts and running a full build. During development, I still only had around 100 of the nearly 2,100 posts included. Even with the (proven) faster build times, I was still somewhat hesitant to load everything in. Perhaps I was afraid that it wouldn’t build or it would actually take forever and the initial promising results were just a fluke. I’d be SOL if I did all this work for a second time, only to encounter the same exact issue again.
With that, I copied over the remaining posts, held my breath, and ran a full build.
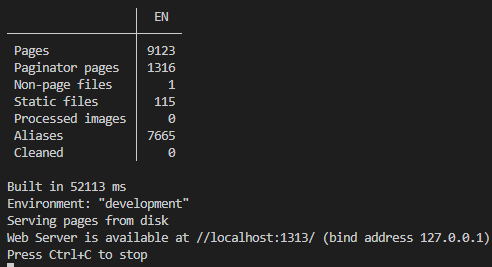
52 seconds. For the entire site with 2,100 posts, 6 or so unique top-level pages, 14 categories and their pages, and 3,500 tags and their pages.
Jekyll could only manage a similar build time with category/tag pages disabled, as well as a cap of 70 or so posts.
I have seen even faster build times in my brief testing. Some builds ended up around 30s at the fastest. Even at it’s slowest I haven’t seen a longer build time than 80-90 seconds (with deleting the build folder and disabling the fastRender option).
The result of this was a fully local offline copy of E Street Shuffle. One that could be navigated much the same way as the original site, with nearly every post and the basic functionality carried over along with some new things on top.
Other Forms of the Archive
This is a section I wasn’t sure if I’d include or not, and it’s been mentioned here and there a few times. But I did want to go over the archive as a whole and cover the forms the archive is available in.
Of course, the entirety of this write-up so far has mostly been about the Jekyll (and later Hugo) based reproduction of the site.
But there are two other main forms being made available as part of the larger “archive” project. I’ve covered this in my other ESS archive write-ups, but as a reminder.
Markdown/JSON
The “raw” form of the archive, also technically the source which the site is built from. Every post has it’s own folder, with a post.md file and a meta.json file. The .md file is the content of the post converted from HTML to Markdown. The .json file is the data pertaining to the post as grabbed from the site’s API.
It wasn’t enough to simply archive the content of the posts and call it a day. Having the .json file also preserves all of the data associated with the post as well. Stuff like tags/categories, the original source HTML of the post, published/last modified times, and more. Is this the “proper” way to preserve a site like this? I don’t know. But it makes sense to me to have preserved all of this while I had the chance. Having all of that raw data might be a help to others, and could lead to other projects in the future.
The tags, categories, and comments have also been preserved from the site in their own JSON files as well.
PostgreSQL Database Dump
In addition to the above files, a Postgres database has been compiled from all of them. This includes all posts, tags, categories, authors, and even comments as well. Even two views with the list of “published” and “all” posts.
I suppose this is a similar form to the first, just presented a bit nicer. Still not “user-friendly” like the site, and does require knowledge of SQL, but it does compile all of the data together. Perhaps someone could use it for some kind of data analysis or something? I compiled it as it was easier to pull all of the needed posts together compared to having to sort through thousands of individual folders.
My Goals With The Archive
My main goal with this archive was to preserve E Street Shuffle long-term. It is a great resource, and one I feel is worth keeping around in some form (or multiple forms in this projects case).
Nothing on the internet lasts forever, it’s foolish to expect that. The site will eventually disappear, it is a “when” not an “if”. Although thanks to this archive, it will remain available for the foreseeable future.
Part of this was why I had planned from the start to make it open source. Anyone can download the repositories and have an offline local copy of E Street Shuffle. Additionally, the Hugo site repository can be downloaded and you can build/run the site locally on your own machine, no internet required. Again, all of this is done in the name of ensuring that E Street Shuffle remains available for the foreseeable future.
Since the shutdown was announced and the bookshelf collection started, around 500 posts have disappeared from the site. The bulk of these were not archived anywhere, and for all intents and purposes are gone forever. Sure, they’re being preserved in book form via the “Bookshelf Collection”, but between the high cost and limited run availability, these fail when it comes to preserving the site and it’s content long-term.
I don’t fault Ken for the approach, he simply wanted physical proof of what he spent the last eight years of his life doing. If I could have a printed version of all my bullshit ramblings over the years, I’d likely do the same. But, for these books to be the only archive being made available doesn’t work.
For all these reasons, I felt compelled to do something. I’ve seen a number of sites disappear over the years, and some are now completely inaccessible. I didn’t want the same to happen to E Street Shuffle.
Closing and Thanks
I say this in nearly every long-form writeup I’ve done, but I didn’t intend for this to be as long as it is. This post alone absolutely dwarfs basically anything else I’ve ever written. And there were many parts I cut out or trimmed which could’ve made it even longer. But, I felt it was worth it to tell this story right and to the best of my ability.
I want to thank Ken Rosen for being supportive of my efforts. When I first wrote to him in December 2025, a part of me was expecting him to tell me to stop. To shut my work down before it even got started. Thankfully he didn’t, which I am thankful for. He was accepting of the idea, even a bit baffled that anyone would go through the effort. I am also thankful to Ken for allowing me to address the readers of E Street Shuffle as part of the final new post on the site. My words are now forever included as a small part of the legacy of E Street Shuffle, which probably baffles me more than my work baffled Ken.
I’m really not sure how to wrap this up, never been that great at conclusions or summarizing my thoughts. As you can clearly see, I can ramble like there is no tomorrow, but wrapping all of that up in a nice little bow has never been a strong suit of mine.
The archive was started in November 2025. As I write this, it is May 29th 2026. When I started, I didn’t have a clue of the scale it would eventually grow to, nor did I have a clue just how long it would take. Frankly I thought I’d have it all wrapped up shortly after the shutdown, with minimal downtime between that and an archive being available to the readers of ESS. I do apologize for the lack of basically any word since January, although until now there wasn’t a ton to show. My goal was to actually finish this project and have something presentable before moving on. Sure, I could’ve written a ton of update posts but why bother when no one would’ve read them anyway. I suppose you can look at this incredibly long post as all of those posts rolled into one.
God it’s such a relief to finally get this project off my mind.
Thanks for Reading! Brian (May 29th, 2026)